-A little asymmetry of distribution is expected when the sample size is small (i.e., <30)
even it comes from a standard normal distribution
-When sample size is large,
further normality examination should be based on normality test in the next tab
Normality test for log-transformed data
Attention should be paid if there is a large number of outliers in either tail,
which violates the normality assumption.
The dots should follow the straight line if they come from normal distribution.
Then the t-test is recommended. If not, please use the Wilcoxon signed-rank test.
Key summary statistics
The observed sample statistics were:
Hypothesis of the t-test
We are testing the null hypothesis that the means of each population equal
P-value from t-test:
A low P value (e.g., <0.05) suggests that your sample provides enough evidence that you can reject the null hypothesis.
About this test
This non-parametric test is less powerfull than parametric tests (including the t-test). It is used when data do not follow the normal distribution.
However, it could be an alternative when the log-transformed data distribution fails to meet normality requirement.
This test is also called Mann–Whitney U test, and Mann–Whitney–Wilcoxon (MWW).
Hypothesis of the Wilcoxon rank-sum test
The null hypothesis is that it is equally likely that a randomly selected value from one sample will
be less than or greater than a randomly selected value from a second sample. Note, we use two-sided test here as default.
P-value from Wilcoxon rank-sum test
A low P value (e.g., <0.05) suggests that your sample provides enough evidence that you can reject the null hypothesis.
If either group follow normal distribution, it should follow a bell shape
Please note:
-A little asymmetry of distribution is expected when sample size is small (<30)
even it comes from a standard normal distribution
-When sample size is large,
further normality examination should rely on normality test in the next tab
Normality test for log-transformed data
Attention should be paid if there is a large number of outliers in either tail,
which violates the normality assumption.
The dots should follow the straight line if they come from normal distribution.
Then the t-test is recommended. If not, please use the Wilcoxon signed-rank test.
File 1
File 2
Key summary statistics
The observed sample statistics were:
Hypothesis of the t-test
We are testing the null hypothesis that the means of each population equal
P-value from t-test:
A low P value (e.g., <0.05) suggests that your sample provides enough evidence that you can reject the null hypothesis.
About this test
This non-parametric test is a less powerfull than parametric tests (including the t-test). It is used when data do not follow the normal distribution or sample size is too small to tell.
However, it could be an alternative when the log-transformed data distribution fails to meet normality requirement.
Hypothesis of the Wilcoxon signed-rank test
compare two related samples, matched samples, or repeated measurements on a single sample to assess whether their population mean ranks differ
P-value from Wilcoxon signed-rank test:
A low P value (e.g., <0.05) suggests that your sample provides enough evidence that you can reject the null hypothesis.
About this test
This non-parametric test is less powerfull than parametric tests (including the t-test). It is used when data do not follow the normal distribution.
However, it could be an alternative when the log-transformed data distribution fails to meet normality requirement.
This test is also called Mann–Whitney U test, and Mann–Whitney–Wilcoxon (MWW).
Hypothesis of the Wilcoxon rank-sum test
The null hypothesis is that it is equally likely that a randomly selected value from one sample will
be less than or greater than a randomly selected value from a second sample. Note, we use two-sided test here as default.
P-value from Wilcoxon rank-sum test
A low P value (e.g., <0.05) suggests that your sample provides enough evidence that you can reject the null hypothesis.
Purpose
C-REx enables gene group expression comparison within or across samples.
A quick instance where our method could be helpful:
Suppose you have a group of genes of unknown function , such as a novel family of transcription factors (TF).
You want to test a hypothesis that this novel TF gene group could be activated in a specific stress condition, such as heat stress.
C-REx provides a data-processing pipeline to enable statistical testing (via Student t-test/Wilcoxon signed-rank test) to determine whether RNA expression patterns are significantly different between stress and non-stress samples.
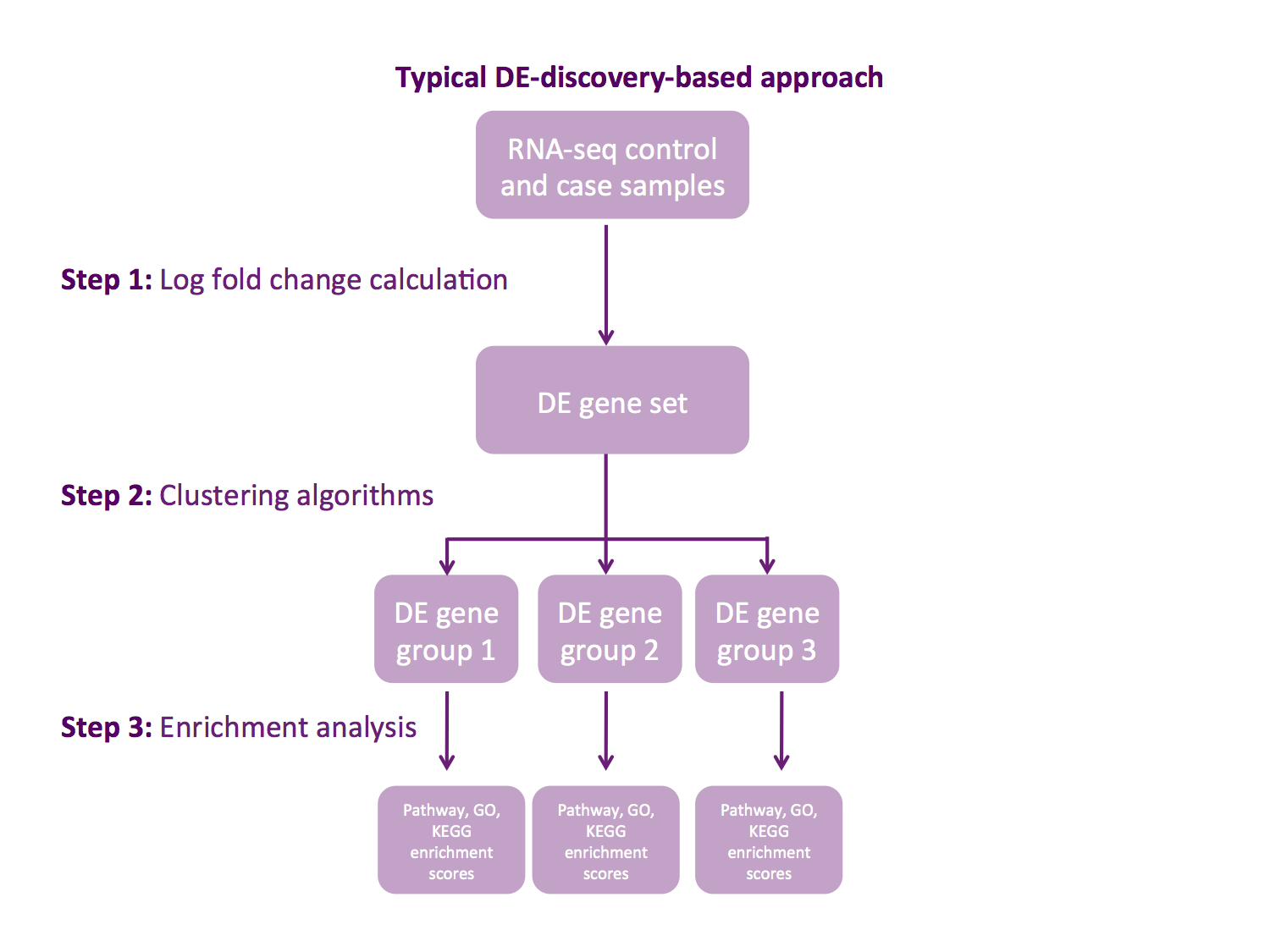
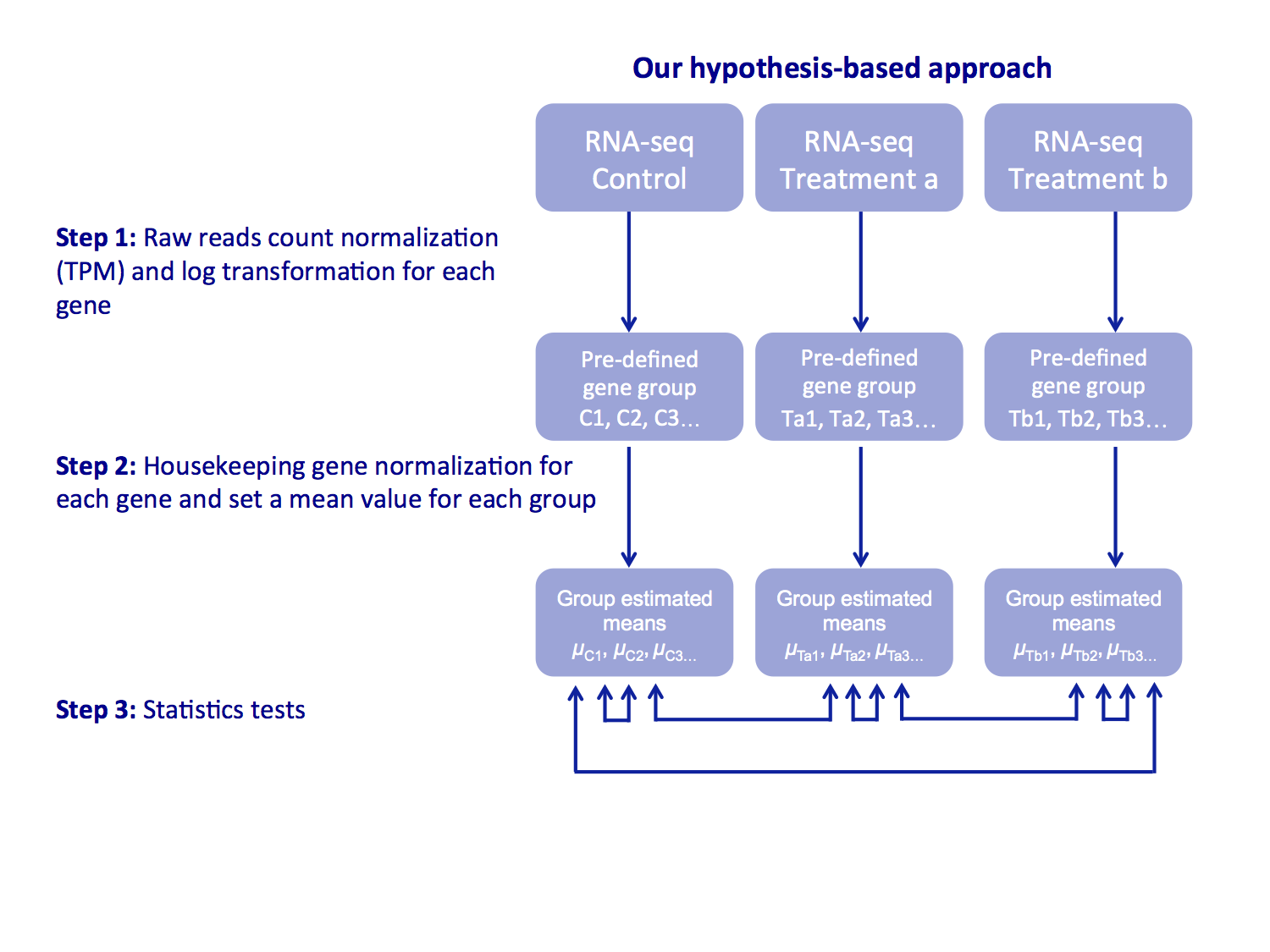
The difference between the typical differential expression (DE), discovery-based approach and our group-to-group RNA expression comparison is illustrated below.
We use a distribution of gene expression values for gene group rather than DE gene sets where gene expression is analyzed individually.
Features
1. We provide a webtool to transform your FPKM/TPM RNA dataset into normal distributions, which enables student t-test for downstream analysis
2. Visualization of log-transformed gene group expression distribution and draw QQ-plot to test normality
3. Use housekeeping gene to normalize across sample gene group expression level
4. T-test on gene groups within a sample or across samples
5. An alternative non-parametric Wilcoxon signed-rank test is also provided if log-transformed distribution does not follow normal distribution
Upload input file format
-Should be in csv, separated by comma, NOT zipped!
-Has 3 columns, namely Gene ID, Gene Expression value (TPM/FPKM), Gene Group
-If you are comparing the same group of genes under two conditions, genes with TPM or FPKM values smaller than 1 in both condition should be removed. Usually such small measurement is not reliable.
-Also, please use the gene group label 'housekeeping genes' to annotate housekeeping genes, some bad examples would be Housekeeping Genes, housekeeping, HOUSEKEEPING...